robots.txtとは?役割やSEOで失敗しないための基本設定を紹介

Webサイトの健全な成長と検索エンジンからの適切な評価は、デジタル戦略において不可欠な要素です。
その根幹を支える技術の一つが「robots.txt」というファイルです。
本記事では、robots.txtの役割からAI時代に対応した設定方法まで、その本質を体系的に解説いたします。
この記事でわかること
- robots.txtはクローラーの動きを制御しサイトのクロールを最適化するファイル
- 検索エンジンだけでなくAI学習用クローラーの制御がSEO上重要
- 正しい書き方を学び、Google Search Consoleでテストすることが設定ミスの防止につながる
- TKwriteworksの無料相談を利用すれば、自社サイトの課題や改善点がわかる
\ 60分間無料で相談可能! /
目次
robots.txtの役割とSEOにおける重要性

この章では、robots.txtがどのようなファイルで、なぜSEOにおいて不可欠なのか、その基本的な役割と目的を初心者にも分かりやすく解説します。
専門用語を避け、クローラーとの関係性からその重要性を紐解いていきます。
robots.txtとは?Webサイトとクローラーの交通整理役
robots.txtとは、Webサイトのルートディレクトリ*に設置されるテキストファイルです。
その本質的な役割は、Googlebotに代表される検索エンジンのクローラーというロボットに対し、サイト内のどのページを巡回してよいか、あるいはどのページには立ち入らないでほしいかを伝えることにあります。
いわば、ウェブサイトという広大な土地における交通整理役であり、クローラーの動きを秩序立てて導くための最初の接点となるのです。
このファイルを通じて、サイト運営者はクローラーの活動を能動的に制御することが可能になります。
*ルートディレクトリ…階層構造の最上部にあるディレクトリのこと。すべてのファイルやフォルダの起点となる根の役割。
なぜrobots.txtが必要なのか?3つの主な目的
robots.txtの設置は、主に3つの戦略的目的からその必要性が論じられます。
第一に、クロールバジェットの最適化です。
検索エンジンが一つのサイトに割り当てるクロール量は有限であり、このリソースを重要度の低いページに消費させず、評価されるべき重要なページへ優先的に誘導することが求められます。
第二の目的は、低品質・重複ページのクロール防止です。
検索結果の自動生成ページやパラメータ付きURLなど、内容が乏しい、あるいは重複するページへのクロールを未然に防ぎ、サイト全体の品質評価を維持します。
第三に、非公開ページのアクセス制御が挙げられます。
会員専用ページや開発中のテストページなど、一般に公開すべきでない領域へのクローラーのアクセスを制限する役割を担います。
クロールについては以下の記事でも詳しく解説していますので、ぜひ参考にしてください。
あわせて読みたい


クロールとは?サイトが検索表示されない3つの原因と最適化する方法
Webサイトの成果を最大化する上で、検索エンジン最適化(SEO)は不可欠な戦略です。 そのSEOの全ての施策の起点となるのが「クロール」という概念の理解に他なりません…
robots.txtではできないこと
robots.txtの役割を理解する上で、その限界を知ることは極めて重要です。
専門家の間でも強調される点として、robots.txtはあくまでクロールをお願いするものであり、検索結果への表示を完全に防ぐものではないという事実があります。
たとえクロールを拒否したページでも、外部サイトからリンクが張られている場合、その存在が検索エンジンに認識され、URLのみが検索結果に表示されることがあります。
ページを確実に検索結果から除外したい場合は、robots.txtではなく、対象ページのHTMLにnoindexメタタグを記述するという、より直接的な手法を用いる必要があります。
robots.txtの設定方法がわからないという方は、ぜひTKwriteworksの無料相談をご利用ください。
【基本ルール】robots.txtの書き方と主要なディレクティブ
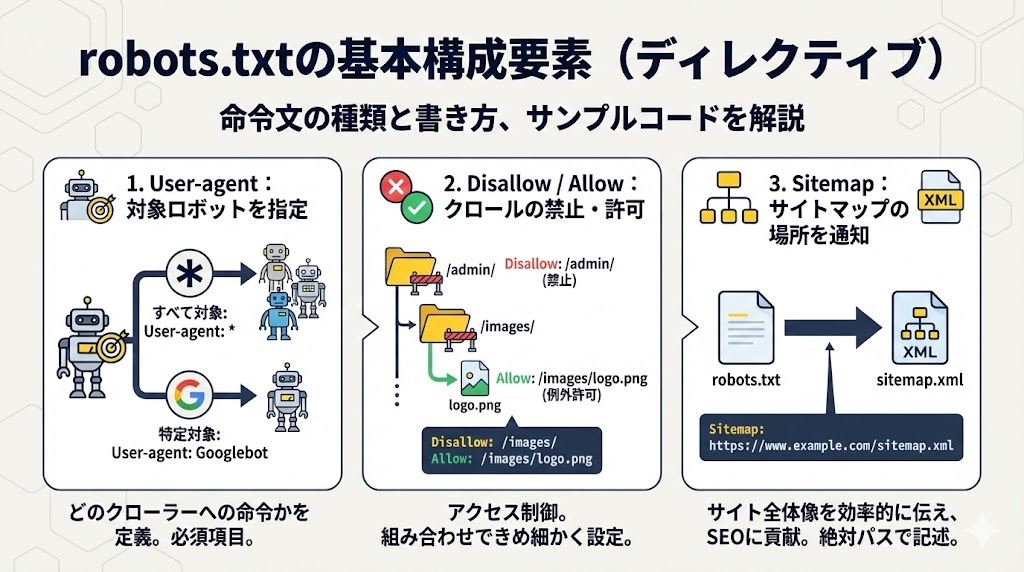
ここでは、robots.txtを構成する基本的なディレクティブと呼ばれる命令文の種類と、それぞれの書き方を具体的に解説します。
コピーして使えるシンプルなサンプルコードを交えながら、誰でも基本構造を理解できるように説明します。
User-agent:命令の対象となるロボットを指定する
robots.txtの記述は、どのクローラーに対する命令なのかを定義する「User-agent」ディレクティブから始まります。
これは、ルールの適用対象を明確にするための必須項目です。
すべてのクローラーを対象とする場合は、ワイルドカードであるアスタリスク「」を使用します。
User-agent:
一方、Googleのウェブ検索クローラーであるGooglebotのみに特定の指示を与えたい場合は、以下のように固有名を指定します。
User-agent: Googlebot
このように、対象を特定することで、クローラーごとに異なるクロールルールを設けることが可能となります。
Disallow / Allow:クロールの禁止と許可を指示する
サイト内の特定領域へのアクセス制御を担うのが、「Disallow」と「Allow」です。
「Disallow」は、指定したディレクトリやファイルへのクロールを禁止する命令です。
例えば、管理画面ディレクトリへのアクセスをすべて拒否する場合は、次のように記述します。
Disallow: /admin/
対して「Allow」は、Disallowで禁止された領域内であっても、特定のファイルやサブディレクトリへのクロールを例外的に許可する際に用います。
例えば、画像ディレクトリ全体は禁止しつつ、その中の特定の画像ファイルだけは許可したい、といった複雑な制御を実現できます。
Disallow: /images/
Allow: /images/logo.png
この二つを組み合わせることで、きめ細やかなクロール制御が実現します。
Sitemap:XMLサイトマップの場所を通知する
SEOにおいて重要なのは、クローラーにサイトの全体像を効率的に把握させることです。
そのために用いられるのが「Sitemap」ディレクティブです。
この記述により、サイト内に存在する全ページのリストであるXMLサイトマップのURLをクローラーに明示的に通知できます。
Sitemap: https://www.example.com/sitemap.xml
robots.txtはクローラーが最初に訪れる場所であるため、ここにサイトマップの場所を記しておくことで、クローラーはサイト構造を迅速に理解し、より網羅的なクロールを行うことが可能になります。
なお、URLは必ず絶対パスで記述する必要があります。
サイトマップについては以下の記事でも詳しく解説していますので、ぜひ参考にしてください。
あわせて読みたい

サイトマップとは?XML/HTMLの違いや効果・作成方法まで紹介
Webサイトの価値を検索エンジンとユーザー双方に正しく伝える上で、サイトマップの存在は不可欠です。 しかし、その重要性を認識しつつも、技術的な複雑さから導入をた…
AIクローラーを制御する方法
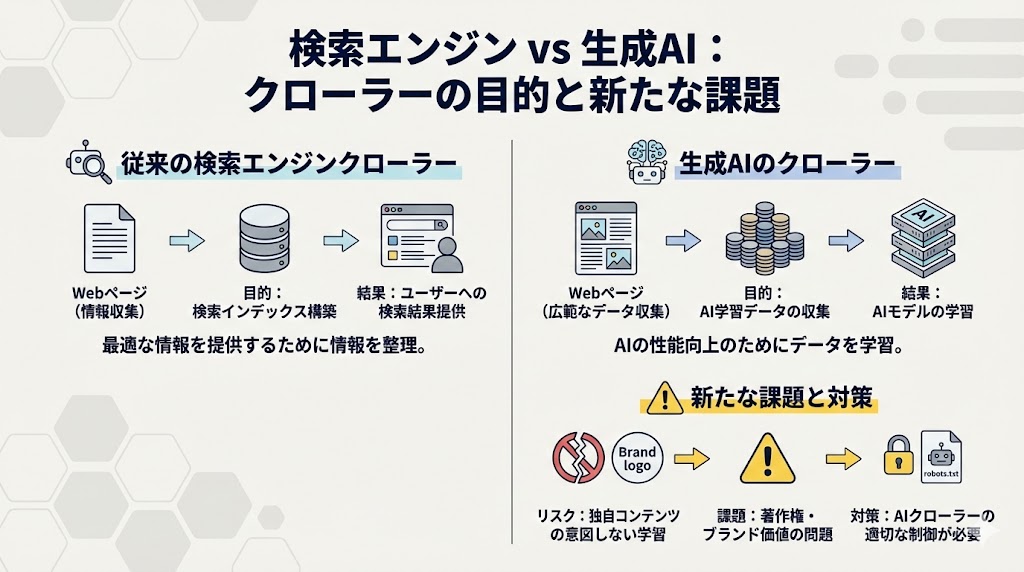
現在のSEOでは、従来の検索エンジンだけでなく、生成AIの学習用クローラーへの対応が不可欠です。
この章では、AIクローラーの種類と、それらをrobots.txtで制御するための最新の記述方法について解説します。
検索エンジンと生成AIのクローラーの違いとは?
従来の検索エンジンクローラーの目的は、Webページの情報を収集し、検索インデックスを構築することにあります。
これにより、ユーザーの検索クエリに対して最適な情報を提供します。
一方、生成AIのクローラーの主目的は、AIモデルの学習データとして、広範なテキストや画像データを収集することです。
サイト運営者にとっては、自社の独自コンテンツが意図せずAIの学習に利用され、著作権やブランド価値の観点から問題が生じるリスクがあります。
そのため、これらのAIクローラーを適切に制御する必要性が高まっています。
主要なAIクローラーのUser-agent一覧
現在、コンテンツ保護の観点から制御を検討すべき主要なAIクローラーが存在します。
各社はクローラーのUser-agent名を公式に公開しており、サイト運営者はこれらをrobots.txtで指定することでアクセスを制御できます。
以下に代表的なものを挙げます。
主要なAIクローラー
- Google-Extended:Google社のAIモデル(Vertex AIなど)用
- ChatGPT-User:OpenAI社のGPTモデル用
- PerplexityBot:Perplexity AI社のモデル用
- ClaudeBot:Anthropic社のClaudeモデル用
これらのUser-agentを把握し、自サイトのコンテンツポリシーに応じて適切な対応をとることが、ウェブサイト運営における新たな責務と言えるでしょう。
AI学習用のクロールを拒否する具体的な記述例
自社サイトのコンテンツがAIモデルの学習データとして利用されることを防ぎたい場合、robots.txtに明確な拒否ルールを記述します。
方法は非常にシンプルです。
対象となるAIクローラーのUser-agentを指定し、サイト全体へのアクセスを禁止する「Disallow: /」を記述します。
例えば、ChatGPT-Userからのクロールを拒否する場合は、以下の一文を追加します。
User-agent: ChatGPT-User
Disallow: /
これにより、コンテンツの無断利用リスクを低減し、知財を保護するための第一歩を踏み出すことができます。
【コピペOK】サイトの種類別robots.txt設定サンプル
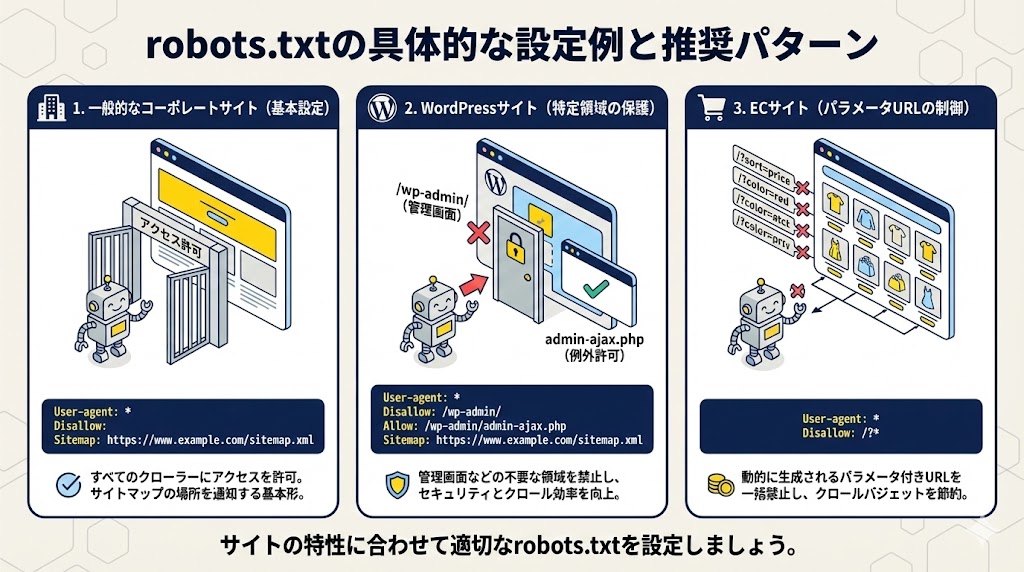
理論だけでなく、すぐに実践で使えるよう、一般的なサイトの種類に応じたrobots.txtの設定サンプルを紹介します。
ご自身のサイトに最も近いものを選び、カスタマイズの土台として活用してください。
一般的なコーポレートサイトの基本設定
多くのコーポレートサイトや小規模なブログでは、特にクロールを制限する必要がない場合がほとんどです。
このようなサイトにおけるrobots.txtの役割は、すべてのクローラーに対してサイト全体へのアクセスを許可し、サイトマップの場所を親切に伝えることに集約されます。
最もシンプルかつ標準的な設定は以下の通りです。
User-agent:
Disallow:
Sitemap: https://www.example.com/sitemap.xml
「Disallow:」の値を空にすることで、いかなるページのクロールも禁止しないという意思表示になります。
これが、健全なサイト運営の基本形です。
WordPressサイトで注意すべき設定
世界で最も普及しているCMSであるWordPressは、その構造上、クロール制御において特有の配慮が求められます。
具体的には、サイトの管理画面や、システムのコアファイルが含まれるディレクトリなど、訪問者に見せる必要がなく、セキュリティ上もクロールされるべきでない領域が存在します。
これらの領域へのクロールを禁止することは、クロールバジェットを最適化し、不要なリスクを回避する上で不可欠です。
推奨される設定例は以下の通りです。
User-agent:
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.example.com/sitemap.xml
ECサイトにおけるパラメータ付きURLの制御例
ECサイトでは、価格での並び替えや色での絞り込みといった機能により、「?sort=price」のようなパラメータが付与されたURLが動的に大量生成されます。
これらのURLは、表示内容はわずかに異なるものの、実質的には重複コンテンツと見なされる可能性があります。
クローラーがこれらのページを無数に巡回することは、クロールバジェットの深刻な浪費につながります。
これを防ぐため、ワイルドカード「」を用いてパラメータを含むURLへのクロールを一括で禁止します。
User-agent:
Disallow: /?
この一行が、ECサイトのSEO健全性を保つ上で極めて重要な役割を果たします。
やってはいけない!robots.txtの致命的な設定ミスと注意点
最後に、初心者が特に注意すべき致命的な設定ミスとその回避策を解説します。
これらのポイントを押さえることで、設定を間違えてサイトが検索結果から消えてしまうという最悪の事態を防ぐことができます。
サイト全体をDisallowしてしまう最も危険なミス
robots.txtの設定において、最も致命的かつ発生しやすいミスが、サイト全体へのクロールを意図せずブロックしてしまうことです。
具体的には、以下のたった一行の記述が原因となります。
User-agent:
Disallow: /
この「Disallow: /」は、ルートディレクトリ以下すべてをクロールしないでくださいという意味を持ちます。
結果として、検索エンジンはサイト内のどのページにもアクセスできなくなり、やがて検索結果から貴社のサイトが完全に姿を消すという、ビジネスにとって壊滅的な事態を招きます。
この記述は、サイトを意図的に非公開にする場合を除き、絶対に避けなければなりません。
robots.txtとnoindexタグの役割の違いと使い分け
技術的なSEOにおいて、しばしば混同されるのがrobots.txtの「Disallow」と「noindexメタタグ」の役割です。
両者の違いを明確に理解することが、適切なサイト制御の鍵となります。
「Disallow」は、あくまでクローラーの巡回を拒否する指示です。
対して「noindex」は、クローラーの巡回は許可した上で、そのページを検索結果に表示しないよう指示する命令です。
確実に検索結果から除外したいページには、クロールを許可した上でnoindexタグを設置するのが正しいアプローチです。
Disallowで指定しても、被リンク経由でインデックスされる可能性があるため、目的応じた使い分けが不可欠です。
CSSやJavaScriptファイルのクロールをブロックしない
現代のWebサイトは、CSSによってデザインが、JavaScriptによって動的な機能が制御されています。
Googleは、ユーザーが実際に閲覧する画面と同じようにページを評価するため、これらのリソースファイルもクロールし、レンダリングします。
もし、robots.txtでCSSやJavaScriptファイルが格納されているディレクトリをDisallowに指定してしまうと、Googleはページの正しい見た目や機能を理解できません。
結果として、コンテンツを正しく評価できず、検索順位の低下につながる恐れがあります。
原則として、これらのリソースファイルへのクロールは常に許可すべきです。
robots.txtとはについてよくある質問
最後に、robots.txtに関して多くの人が抱く疑問にQ&A形式でお答えします。
記事の本文では触れきれなかった、より実践的な内容をまとめましたので、ぜひ参考にしてください。
タップで該当の質問にジャンプ
robots.txtファイルが存在しない場合、SEOに悪影響はありますか?
robots.txtファイルが存在しない場合、サーバーは404エラー(Not Found)を返します。
検索エンジンはこれを「すべてのページのクロールを許可する」と解釈するため、直ちにサイトが検索結果から消えるといった深刻な悪影響はありません。
しかし、クロールを制御する意思がない場合でも、すべてのクロールを明示的に許可する空のrobots.txtファイルを設置することが推奨されています。
これにより、サーバーへの不要な404リクエストを防ぎ、クローラーに対して明確な意思表示を示すことができます。
サイトマップ(sitemap.xml)は複数指定できますか?
可能です。
特に数万ページを超えるような大規模サイトでは、サイトマップをカテゴリ別や日付別などで複数に分割して管理することが一般的です。
その場合、robots.txtにはSitemapディレクティブを複数行記述することで、すべてのサイトマップの場所をクローラーに通知できます。
Sitemap: https://www.example.com/sitemap-posts.xml
Sitemap: https://www.example.com/sitemap-pages.xml
このように1行に1つのURLを記述することで、クローラーはサイトの全容をより効率的に把握できるようになります。
特定のAIクローラーだけを拒否し、Googlebotは許可する書き方は?
User-agentを個別に指定することで、クローラーごとに異なるルールを適用することが可能です。
例えば、AIクローラーであるChatGPT-Userのクロールは拒否しつつ、検索エンジンであるGooglebotのクロールは全面的に許可したい場合は、以下のように記述します。
User-agent: ChatGPT-User
Disallow: /
User-agent: Googlebot
Disallow:
このように、User-agentごとにブロックを分けて記述することで、特定のクローラーを選択的に制御できます。
これは、コンテンツの利用目的をコントロールする上で非常に有効な手法です。
まとめ
本記事では、robots.txtの基本的な役割から、AIクローラーへの対応といった先進的なトピックまでを網羅的に解説しました。
robots.txtは、Webサイトと検索エンジンとの対話を司る重要なファイルであり、その適切な設定はクロール効率を最適化し、SEOの成果を最大化する上で不可欠です。
設定ミスは大きなリスクを伴いますが、正しい知識を身につければ、サイトの価値を守り育てる強力な武器となります。
また、その他のテクニカルSEOについては以下の記事でも詳しく解説していますので、ぜひ参考にしてください。
あわせて読みたい

テクニカルSEOとは?コンテンツSEOとの違いや主な施策を紹介
テクニカルSEOとは、Webサイトの内部構造を技術的に最適化し、検索エンジンのクロールやインデックスを円滑にするための施策です。 2026年現在、AI OverviewsやCore Web…
\ 60分間無料で相談可能! /